Recorridos de árboles
Ahora que hemos examinado la funcionalidad básica de nuestra estructura de datos árbol, es hora de mirar algunos patrones de uso adicionales para los árboles. Estos patrones de uso se pueden dividir en las tres maneras en que tenemos acceso a los nodos del árbol. Hay tres patrones de uso común para visitar todos los nodos de un árbol. La diferencia entre estos patrones es el orden en que es visitado cada nodo. Llamamos a estas visitas de los nodos un “recorrido”. Los tres recorridos que vamos a ver se llaman preorden, inorden y postorden. Comencemos definiendo estos tres recorridos con más cuidado, para luego mirar algunos ejemplos donde estos patrones son útiles.
- preorden
- En un recorrido en preorden, visitamos primero el nodo raíz, luego recursivamente realizamos un recorrido en preorden del subárbol izquierdo, seguido de un recorrido recursivo en preorden del subárbol derecho.
- inorden
- En un recorrido en inorden, realizamos recursivamente un recorrido en inorden en el subárbol izquierdo, visitamos el nodo raíz, y finalmente hacemos un recorrido recursivo en inorden del subárbol derecho.
- postorden
- En un recorrido en postorden, realizamos recursivamente recorridos en postorden del subárbol izquierdo y del subárbol derecho seguidos de una visita al nodo raíz.
Veamos algunos ejemplos que ilustran cada uno de estos tres tipos de recorridos. Primero veamos el recorrido en preorden. Como ejemplo de un árbol a recorrer, representaremos este libro como un árbol. El libro es la raíz del árbol, y cada capítulo es un hijo de la raíz. Cada sección dentro de un capítulo es un hijo del capítulo, y cada subsección es un hijo de su sección, y así sucesivamente. La Figura 5 muestra una versión limitada de un libro con sólo dos capítulos. Tenga en cuenta que el algoritmo de recorrido funciona para árboles con cualquier número de hijos, pero nos limitaremos a los árboles binarios por ahora.

Hay tres manera de recorrer un árbol: en inorden, preorden y postorden. Cada una de ellas tiene una secuencia distinta para analizar el árbol como se puede ver a continuación:
- INORDEN
- Recorrer el subarbol izquierdo en inorden.
- Examinar la raíz.
- Recorrer el subarbol derecho en inorden.
- PREORDEN
- Examinar la raíz.
- Recorrer el subarbol izquierdo en preorden.
- recorrer el subarbol derecho en preorden.
- POSTORDEN
- Recorrer el subarbol izquierdo en postorden.
- Recorrer el subarbol derecho en postorden.
- Examinar la raíz.
A continuación se muestra un ejemplo de los diferentes recorridos en un árbol binario.
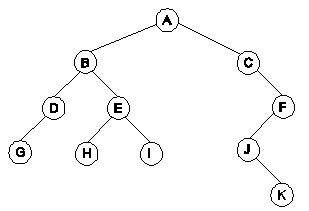
- Inorden: GDBHEIACJKF
- Preorden: ABDGEHICFJK
- Postorden: GDHIEBKJFCA

EJERCICIO
ORDENAR

PRE-ORDEN
ALGORITMO:
ALGORITMO:
RAIZ, IZQUIEDO, DERECHO
22,15,3,1,8,7,4,13,9,12,10,20,40,30,23,34,45,48,53,51
IN-ORDEN
IN-ORDEN
IZQUIERDO-RAIZ-DERECHO
1,3,4,7,8,9,10,12,13,15,23,30,34,40,45,48,51,53
POST-ORDEN
IZQUIERDO-DERECHO-RAIZ
1,4,7,10,12,9,13,8,3,20,15,23,34,30,31,53,48,45,40,22
Pila semántica en un analizador sintáctico

Árbol De Expresiones o Árbol Semántico

También se la llama tabla de nombres o tabla de identificadores y tiene dos funciones
principales:
- Efectuar chequeos semánticos.
- Generación de código.
Permanece sólo en tiempo de compilación, no de ejecución, excepto en aquellos casos en
que se compila con opciones de depuración.
La tabla almacena la información que en cada momento se necesita sobre las variables del
programa, información tal como: nombre, tipo, dirección de localización, tamaño, etc.

Código Arboles binarios
In-orden, pos-orden,pre-orden
1,3,4,7,8,9,10,12,13,15,23,30,34,40,45,48,51,53
POST-ORDEN
IZQUIERDO-DERECHO-RAIZ
1,4,7,10,12,9,13,8,3,20,15,23,34,30,31,53,48,45,40,22
Pila semántica en un analizador sintáctico
El diseño ascendente se
refiere a la identificación de aquellos procesos que necesitan computarizarse
con forme vayan apareciendo, su análisis como sistema y su codificación, o
bien, la adquisición de paquetes de software para satisfacer el problema inmediato.

Las pilas y colas son
estructuras de datos que se utilizan generalmente para simplificar
ciertas operaciones de programación. Estas
estructuras pueden implementarse mediante arrays o listas enlazadas.
Pila: colección de datos a los cuales se les
puede acceder mediante un extremo, que se conoce generalmente como tope. Las pilas tienen
dos operaciones básicas:
Push (para introducir un elemento)ØPop (para extraer un elemento)Sus
características fundamentales es que al extraer se obtiene siempre el último elemento
que acabe de insertarse. Por esta razón también se conoce como estructuras de
datos LIFO, una posible implementación mediante listas enlazadas seria
insertando y extrayendo siempre por el principio de la lista. Las pilas se
utilizan en muchas aplicaciones que utilizamos con frecuencia. Las pilas y colas
son estructuras de datos que se utilizan generalmente para simplificar ciertas operaciones
de programación. Estas estructuras pueden implementarse mediante arrays o listas
enlazadas .Un analizador sintáctico es un autómata de pila que reconoce la
estructura de una cadena de componentes léxicos. En general, el analizador
sintáctico inicializa el compilador y para cada símbolo de entrada llama al analizador
morfológico y proporciona el siguiente símbolo de entrada. Al decir pila semántica no se refiere a que
hay varios tipos de pila, hace referencia a que se debe programar única y
exclusivamente en un solo lenguaje, es decir, no podemos mezclar código de C++
con Visual Basic. Ventajas Los problemas de integración entre los subsistemas
son sumamente costosos y muchos de ellos no se solucionan hasta que la
programación alcanza la fecha límite para la integración total del sistema. Se
necesita una memoria auxiliar que nos permita guardar los datos para poder
hacer la comparación. Objetivo teórico Es
construir un árbol de análisis sintáctico, este raramente se construye como
tal, sino que las rutinas semánticas integradas van generando el árbol de
Sintaxis abstracta. Se especifica mediante una gramática libre de contexto. El
análisis semántico detecta la validez semántica de las sentencias aceptadas por
el analizador sintáctico. El analizador semántico suele trabajar
simultáneamente al analizador sintáctico y en estrecha cooperación. Se entiende
por semántica como el conjunto de reglas que especifican el significado de
cualquier sentencia sintácticamente correcta y escrita en un determinado
lenguaje. Las rutinas semánticas deben realizar la evaluación de los atributos
de las gramáticas siguiendo las reglas semánticas asociadas a cada producción
de la gramática. El análisis sintáctico es la fase en la que se trata de
determinar el tipo de los resultados intermedios, comprobar que los argumentos que tiene un
operador pertenecen al conjunto de los operadores posibles, y si son
compatibles entre sí, etc.
En definitiva, comprobará que el
significado de la que se va leyendo es válido. La salida teórica de la fase de
análisis semántico sería un árbol semántico. Consiste en un árbol sintáctico en
el que cada una de sus ramas ha adquirido el significado que debe tener.
Análisis Semántico
¿Qué es un análisis
semántico?
Bueno se refiere a
los aspectos del significado, sentido o interpretación de el mismo de un
determinado elemento, símbolo, palabra, expresión o representación formal
Determina el tipo
de resultados intermedios y que si los argumentos que tiene un operador pertenecen
al conjunto de los operadores posibles.
Revisa si el
significado de lo que se va leyendo es valido.
El resultado de la
fase de análisis semántico viene siendo lo que se conoce como "árbol semántico"
Árbol De Expresiones o Árbol Semántico
Es una estructura jerárquica
en la cual se registran las operaciones que realiza el programa fuente, en cada
una de las ramas del árbol se registra el valor o significado que este debe
tener y el análisis analiza cuál de los valores registrado en las ramas es
aplicable

ACCIONES SEMÁNTICAS
Dependiendo del
tipo de sentencias, las acciones semánticas pueden agruparse
en: Sentencias de Declaración: Completar la sección de tipos de la Tabla
de
Símbolos.
Sentencias
“ejecutables”: Realizar comprobaciones de tipos entre los operados implicados.
Funciones y
procedimientos: Comprobar el número, orden y tipo de los parámetros actuales en
cada llamada a una función o procedimiento.
Identificación de
variables: Comprobar si un identificador ha sido declarado antes de utilizarlo.
Etiquetas:
Comprobar si hay etiquetas repetidas y validación.
Constantes:
Comprobar que no se utilicen en la parte izquierda de una asignación.
Conversiones y
equivalencias de tipo: Verificación.
Sobrecarga de
operadores y funciones: Detectar y solventar.
Comprobación de
tipo en expresiones
E à
literal {E.tipo = char}
E à
num {E.tipo =
entero}
E à
id {E.tipo
= Consultar_TS(id.entrada)}
E à id
[E1] {id.tipo = Consultar_TS(id.entrada)}
Pila semántica en
un analizador sintáctico
Como
podemos entender un analizador sintáctico ascendente utiliza durante el
análisis una pila. En esta va guardando datos que le permiten ir haciendo las
operaciones de reducción que necesita.
Para incorporar acciones semánticas como lo es construir el árbol sintáctico, es necesario incorporar a la pila del analizador sintáctico ascendente otra columna que guarde los atributos de los símbolos que se van analizando.
Para incorporar acciones semánticas como lo es construir el árbol sintáctico, es necesario incorporar a la pila del analizador sintáctico ascendente otra columna que guarde los atributos de los símbolos que se van analizando.
Generación
de tablas de símbolos y de direcciones
También se la llama tabla de nombres o tabla de identificadores y tiene dos funciones
principales:
- Efectuar chequeos semánticos.
- Generación de código.
Permanece sólo en tiempo de compilación, no de ejecución, excepto en aquellos casos en
que se compila con opciones de depuración.
La tabla almacena la información que en cada momento se necesita sobre las variables del
programa, información tal como: nombre, tipo, dirección de localización, tamaño, etc.
Manejo
de errores semánticos
Los errores semánticos son más sutiles. Un
error semántico se produce cuando la sintaxis del código es correcta, pero la
semántica o significado no es el que se pretendía. La construcción obedece las
reglas del lenguaje, y por ello el compilador o intérprete no detectan los
errores semánticos. Los compiladores e intérpretes sólo se ocupan de la estructura
del código que se escribe, y no de su significado. Un error semántico puede
hacer que el programa termine de forma anormal, con o sin un mensaje de error.
VÍDEO
MAPA MENTAL

Código Arboles binarios
In-orden, pos-orden,pre-orden
public class NodoArbol
{
//miembros de acceso
NodoArbol nodoizquierdo;
int datos;
NodoArbol nododerecho;
//iniciar dato y hacer de este nodo un nodo hoja
public NodoArbol(int datosNodo)
{
datos = datosNodo;
nodoizquierdo = nododerecho = null; //el nodo no tiene hijos
}
//buscar punto de insercion e inserter nodo nuevo
public synchronized void insertar(int valorInsertar)
{
//insertar en subarbol izquierdo
if(valorInsertar < datos)
{
//insertar en subarbol izquierdo
if(nodoizquierdo == null)
nodoizquierdo = new NodoArbol(valorInsertar);
else //continua recorriendo subarbol izquierdo
nodoizquierdo.insertar(valorInsertar);
}
//insertar nodo derecho
else if(valorInsertar > datos)
{
//insertar nuevo nodoArbol
if(nododerecho == null)
nododerecho = new NodoArbol(valorInsertar);
else
nododerecho.insertar(valorInsertar);
}
} // fin del metodo insertar
}
class Arbol { private NodoArbol raiz; //construir un arbol vacio public Arbol() { raiz = null; } //insertar un nuevo ndo en el arbol de busqueda binaria public synchronized void insertarNodo(int valorInsertar) { if(raiz == null) raiz = new NodoArbol(valorInsertar); //crea nodo raiz else raiz.insertar(valorInsertar); //llama al metodo insertar } // EMPIEZA EL RECORRIDO EN PREORDEN public synchronized void recorridoPreorden() { ayudantePreorden(raiz); } //meoto recursivo para recorrido en preorden private void ayudantePreorden(NodoArbol nodo) { if(nodo == null) return; System.out.print(nodo.datos + " "); //mostrar datos del nodo ayudantePreorden(nodo.nodoizquierdo); //recorre subarbol izquierdo ayudantePreorden(nodo.nododerecho); //recorre subarbol derecho } //EMPEZAR RECORRIDO INORDEN public synchronized void recorridoInorden() { ayudanteInorden(raiz); } //meoto recursivo para recorrido inorden private void ayudanteInorden( NodoArbol nodo) { if(nodo == null) return; ayudanteInorden(nodo.nodoizquierdo); System.out.print(nodo.datos + " "); ayudanteInorden(nodo.nododerecho); } //EMPEZAR RECORRIDO PORORDEN public synchronized void recorridoPosorden() { ayudantePosorden(raiz); } //meotod recursivo para recorrido posorden private void ayudantePosorden(NodoArbol nodo) { if( nodo == null ) return; ayudantePosorden(nodo.nodoizquierdo); ayudantePosorden(nodo.nododerecho); System.out.print(nodo.datos + " "); } }Clase controladora:import javax.swing.JOptionPane; public class PruebaArbol { public static void main(String args []) { Arbol arbol = new Arbol(); int valor; String Dato; System.out.println("Insertando los siguientes valores: "); Dato = JOptionPane.showInputDialog("Inserta el numero de nodos que desea ingresar"); int n = Integer.parseInt(Dato); for(int i = 1; i <= n; i++ ) { Dato = JOptionPane.showInputDialog("Dame el " + i + " valor para colocar en el Arbol"); valor = Integer.parseInt(Dato); System.out.print(valor + " "); arbol.insertarNodo(valor); } System.out.println("\n\nRecorrido Preorden"); arbol.recorridoPreorden(); System.out.println("\n\nRecorrido Inorden"); arbol.recorridoInorden(); System.out.println("\n\nRecorrido Postorden"); arbol.recorridoPosorden(); } }
No hay comentarios.:
Publicar un comentario